Python 数据处理之字段去重
在之前遇到的数据中,由于同一部件的可替换不同产品,造成了同一行出现了2次及以上同样的字段和属性值,而只需要其中的一个以及对应值即可,此文记录下处理的过程。
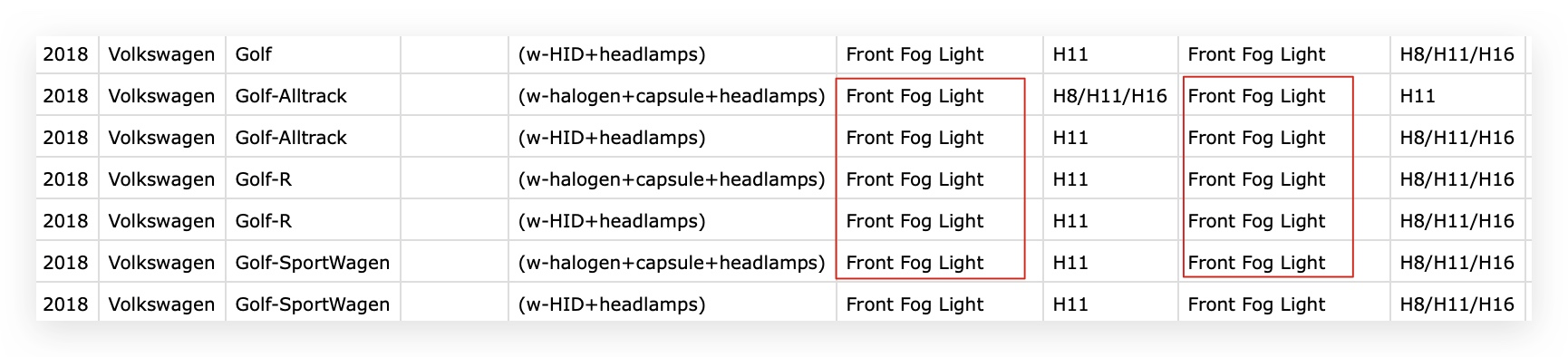
一番分析后,整理了如下的思路来清理重复字段:
- 循环读取每一行
- 用
,分散成数组 - 循环判断索引大于5的元素
para[n] == para[n-2]时表示当前字段重复- 同时跳过重复字段的值
Python 代码实现
import getopt, sys
def go(file_name):
f = open(file_name, 'r')
result = list()
for line in open(file_name):
line = f.readline()
para = line.split(",")
new_line = ""
dump_line = 0
for index in range(len(para)):
if(index <= 5):
new_line = new_line + para[index] +","
continue
else:
if(para[index] == para[index-2]):
dump_line = index
continue
elif(dump_line == index -1):
continue
else:
new_line = new_line + para[index] +","
print new_line
result.append(new_line)
f.close()
open(file_name+'-fix.csv', 'w').write('%s' % '\n'.join(result))
if __name__ == '__main__':
file_name = sys.argv[1]
go(file_name)
执行命令 python fix.py 文件名
将得到处理后的文件 文件名-fix.csv
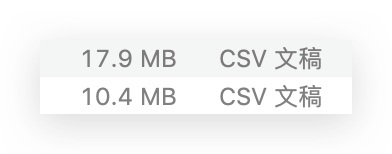
看着文件大小骤减40%,如释重负的感觉:)